Transcend Borders: Software & Design Be the one who understands engineering to know what's possible, design to know what's beautiful, psychology to know what's desirable, business to know what's valuable, and has the courage to act on it (@keshavchan) |
|
|
About 데일리 노트
- 벌서 한 해의 끝에 다다르고 있습니다. 2024년을 마무리하고 2025년을 기다리며 이번 편은 디지털 크리에이터들이 주목해봐야할 2025년 트랜드: Software 편으로 내용을 준비해보았습니다. 다음주에는 주목해봐야할 2025년 트랜드: Design 편이 준비되어 있습니다.
- 다가오는 목요일에는'AI 아바타'와 관련된 주제로 테크잇슈 뉴스레터에 외부 연재하는 글이 기재됩니다. 이 또한 많은 관심 부탁드립니다.
- 그럼, 이번 데일리 노트도 재미있게 읽어나가시길 바라며, 다음주에는 12월 셋째 주 뉴스레터로 다시 찾아뵙겠습니다.
목차
- AI 음성 기반 서비스
- 능동적인 AI 에이전트 서비스
- Software & Design 라이브러리
|
|
|
AI 음성 서비스
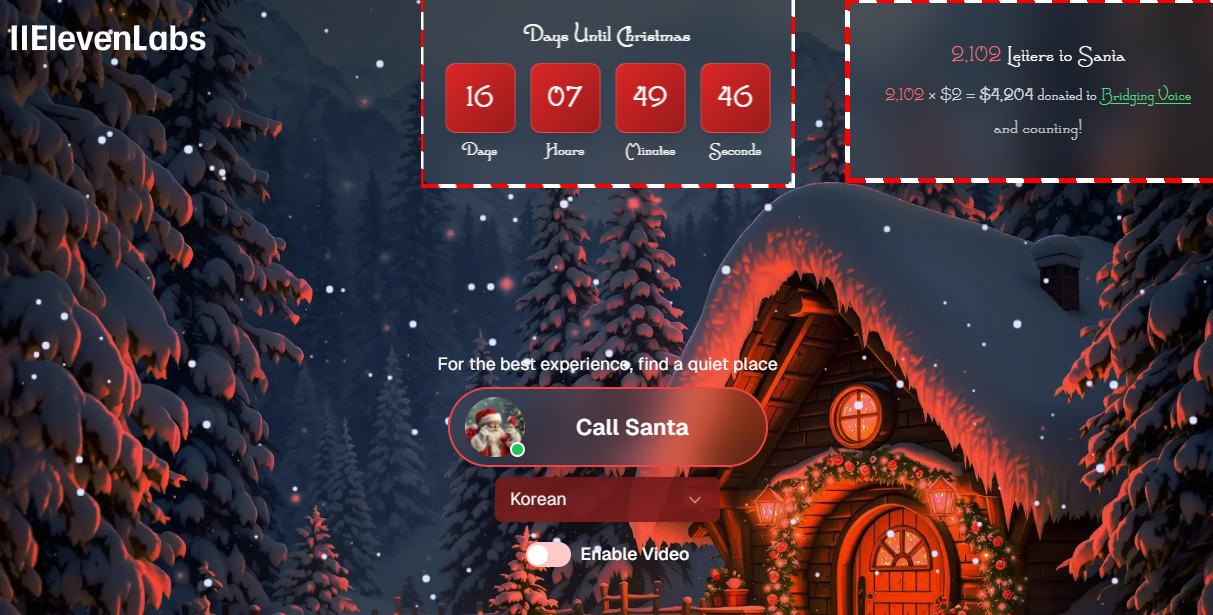
첫번째로 주목할 트랜드는 AI 음성 기반 서비스입니다. 여러 AI 서비스 중, 대중들이 활용하기 쉽고 재미있는 애플리케이션들이 나오고 있는 분야이며, 2025년에는 더욱더 많은 사람들이 음성(Voice)으로 AI와 상호작용 하는 것을 친숙하게 여길 것으로 봅니다. 과거에는 Elevenlabs, Udio Music 등 텍스트-to-음성 기반의 서비스만 출시되었던 반면, 최근에는 음성으로 컴퓨터 디바이스와 소통하는 음성-to-컴퓨터 제어 서비스들이 나타나는 모습입니다.
|
|
|
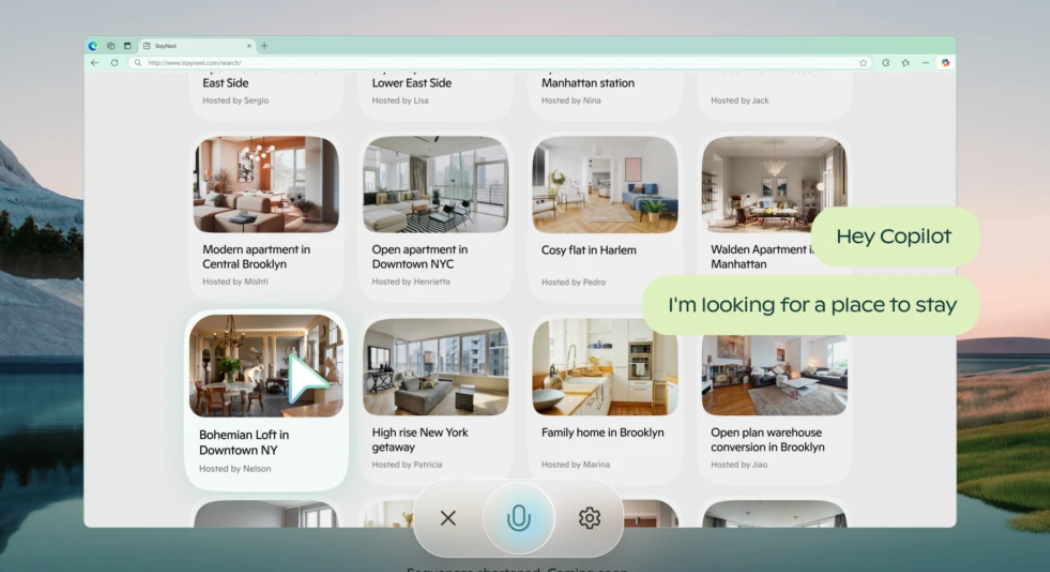
가장 대표적으로 Microsoft Copilot 애플리케이션은 “Copilot Vision” 기능을 출시하며 화면을 볼 수 있는 음성 어시스턴트를 소개했습니다. 사용자는 음성 어시스턴트와의 대화하며 컴퓨터 작업을 수행할 수 있으며, 음성 어시스턴트는 화면 내에서 일어나는 상황에 대한 이해를 기반으로 출력 결과를 보여줍니다. 공식 데모 영상에서 사용자들은 음성 어시스턴트와 상호작용하며 여행 계획을 세우고, 쇼핑/게임을 하는 모습을 볼 수 있습니다. |
|
|
Nvidia, OpenAI 등 범용적인 AI 모델 개발사들뿐만 아니라, Elevenlabs, Hume AI 등 음성 AI 모델 개발사들이 개발 툴 킷들을 발표하며 API를 활용해 음성 AI 서비스를 애플리케이션 내 도입하는 경우가 증가할 것으로 보입니다.
생성형 음성 AI 서비스의 마법은 기존의 텍스트 기반 창작품을 대화형으로 바뀔 수 있다는 데 있습니다. 글로써 창작품이 끝나는 것이 아니라, 이를 음반으로 바꿔보고, 팟캐스트로 만들어 보며 창착 환경이 무한히 확장 시킬 수 있게 되었습니다. 여러 가지 유형의 데이터 유형을 이해할 수 있는 멀티모달 음성 AI 서비스가 나타남에 따라 크리에이티브 창작품들도 다양한 형태를 가질 것으로 보입니다.
|
|
|
능동적인(Proactive) AI 에이전트 서비스
두 번째로 주목할 트랜드는 능동성이 강화된 AI 에이전트 서비스의 등장입니다. 과거의 AI 에이전트 서비스가 정해진 명령 구조에 따라 움직였다면, 앞으로의 AI 에이전트는 입력 프롬프트에 따른 출력 결과를 되짚어보고 능동적으로 행동을 보완해 나가는 형태로 나아갈 것입니다.
능동적인 AI 에이전트 서비스를 가장 먼저 선보인 서비스 분야는 AI 프로그래밍 툴입니다. 최초의 Agentic IDE라고 주장하는 Windsurf 플랫폼의 경우, 사용자가 코드를 입력하는 동안 사용자의 개발 의도를 예측하고 계획을 세워, (i) 자동 완성, (ii) 다단계 편집, (iii) Repository에 걸쳐 전반적인 편집 활동을 자체적으로 수행해 나갑니다. |
|
|
AI 코드 편집기의 진화 과정
출처: Every |
|
|
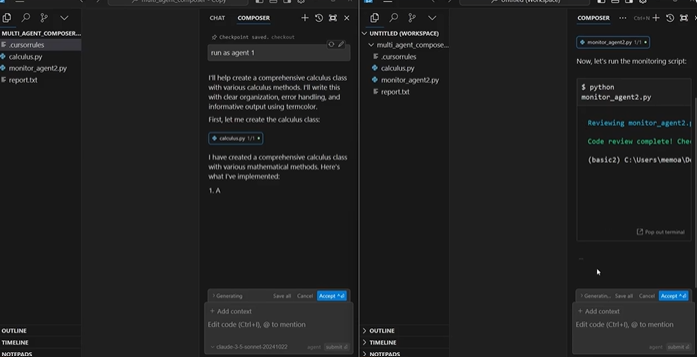
대표 AI 프로그래밍 도구인 Cursor도 v0.43 버전 업데이트를 통해 “Composer Agent”기능을 소개하며 능동적인 프로그래밍 에이전트의 모습을 일부 도입했습니다. 해당 에이전트를 통해 (i) 통합 템플릿 설계, (ii) 프로그래밍 코드의 즉각 수정/재배열, (iii) 프로젝트 셋업을 빠른 속도로 실행할 수 있게 되었습니다.
|
|
|
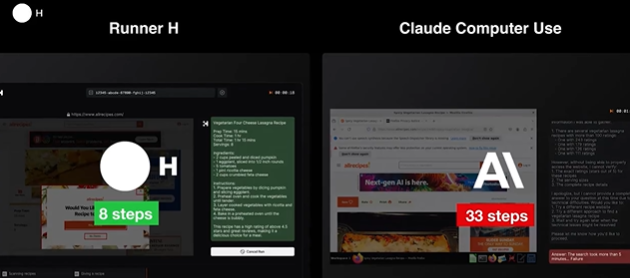
가장 높은 자율성 정도를 보이며 많은 사람들이 주목하고 있는 능동적인 AI 에이전트 프로젝트는 H Company가 출시 예정인 “Runner H” 컴퓨터 제어 에이전트입니다. 원하는 목표를 프롬프트로 입력하면 Runner H 에이전트가 컴퓨터를 스스로 탐색해나가며 복잡하고, 다단계 작업을 마무리 할 수 있는 능력을 가졌기 때문입니다.
컴퓨터 제어 능력을 평가하는 WebVoyager 벤치마크에서 Claude사의 컴퓨터 제어 에이전트보다 개선된 평가 결과를 나온 것으로 알려졌으며, 픽셀 단위까지 웹 인터페이스를 탐색하며 UI 변경에도 자동적으로 적응해 나갈 수 있는 것으로 알려져 있습니다.
데모를 통해서 Runner H 에이전트가 (i) 웹 스크래핑, (ii) 수학 문제 해결, (iii) 실시간 데이터 수집, (iv) 지도 탐색 등을 수행하는 모습을 보여주며 다양한 목적에 걸쳐 자율적인 컴퓨터 에이전트가 활용 될 수 있음을 보였습니다. 현재 서비스가 출시된 상황은 아니며, 대기명단만 열려있는 상황입니다. 해당 서비스가 홍보한 만큼의 능동성을 보일 수 있는지는 지켜봐야 할 대목입니다. |
|
|
웹 스크래핑 활동을 하는 Runner H와 Claude Computer Use 에이전트 바교
|
|
|
능동적인 AI 에이전트 서비스는 산업계와 연구계 모두에서 주목하고 있는 주제인 만큼, AI 프로그래밍 서비스를 필두로 2025년에는 능동적인 AI 에이전트들을 더 많이 찾아볼 수 있을거라 생각합니다. 이렇게 될 경우, AI 에이전트의 플로우를 기획하기 위한 툴 뿐만 아니라, AI 에이전트의 결과를 자동으로 평가(Evaluation)할 수 있는 서비스의 역할도 중요해질 것으로 보입니다. |
|
|
출시/업데이트
- Amazon: re:Invent 연례행사서 대형언어모델 노바(Nova) 시리즈 공개
- Anthropic: Amazon Bedrock 서비스 위에서 Prompt Caching Preview 지원
- Browser Company: Dia — 스마트 브라우저 출시
- Cohere: Rerank 3.5 — 엔터프라이즈 데이터 추론 능력 및 다국어 기능 지원하는 최신 AI 검색 모델
- Every: Extendable Articles — LLM 챗봇을 통해 자료의 출처를 문의할 수 있는 기사
- Exa AI: Exa Websets — AI 애플리케이션을 위한 검색 API
- Google: Chrome DevTools 내 AI 지원 | Google Deepmind — GenCast: 극한 날씨 상황을 예측할 수 있는 AI 모델 | Android OS 업데이트 — Expressive Captions: 언어/소리에 녹아 있는 뉘앙스를 캡션에 드러내는 기능
- Hello Robot: Stretch AI — AI 가정용 로봇 애플리케이션을 구축할 수 있는 오픈 소스 도구, 가이드, 레퍼런스 코드
- Hugging Face: LLaMA-O1 — 논리력(Reasoning) 모델 모음집 | Open-source AI: 2024년 리뷰 | FishSpeech v1.5 — 오픈소스 텍스트-스피치 모델
- Humane: CosmOS — 연결된 IoS 디바이스를 위한 AI 운영 체제
- Microsoft: Copilot Vision Preview: 화면을 보면서 컴퓨터 작업을 도와주는 어시스턴트 | MatterSimV1-1M, MatterSimV1-5M — 다양한 원소, 온도, 압력 등 재료의 특성을 시뮬레이션 하도록 설계된 딥런닝 모델
- Mistral AI: LeChat 챗봇 내 파이썬 실행 가능
- Notion: Action-packed Automations — Zapier 및 Make 등의 플랫폼을 통해 1000개 이상의 도구에 연결하여 데이터베이스 액션 트리거 설정 가능
- Nous Research: Nous DisTrO와 하드웨어를 활용한 15B 파라미터 언어모델 사전 학습
- Open AI: OpenAI o1 공식 버전 출시 | OpenAI Devs Page 복사해 IDE 내 최신 API 활용
- Pleias: 오픈 데이터 기반으로 훈련된 모델군 — Pleias-3B, Pleias-1B, Pleias-350M
- Qodo: Cover — 회귀 테스트를 진행하는 자율 AI 에이전트
- Replit: 검증된 개발자와 매칭 될 수 있는 새로운 바운티 서비스 출시
- Ruliad AI: DeepThought-8B — LLaMA-3.1 모델 기반으로 구축된 오픈소스 논리 모델
- Sailor2: Qwen 2.5 모델 기초 위에 세워지고, 다국어 지원 대형언어모델(0.8B, 8B, 20B 파라미터)을 지원하는 커뮤니티 기반 프로젝트
- Sakana AI — Cycle QD: 서로를 보완하는 전문 에이전트 무리, 평생 학습 토대를 마련하는 모델 통합 연구
- Supabase: AI Assistant v2 — 새로운 기능(ex. Schema Design, Data Query & Charting 등)을 갖춘 v2 어시스턴트 출시 | Cron — DB 내에서 반복작업을 수행할 수 있는 Postgres 모듈
- v0: Figma 디자인 Import 지원
- World Labs: 공간 지능 연구 결과 공개 & 데모
- ZenML: LLMOps Database — 300+개의 실제 LLM 실행 케이스로 채워진 데이터베이스
프로젝트/상품/서비스
에세이/뉴스레터/보고서/논문
|
|
|
출시/업데이트
프로젝트
에세이/뉴스레터/보고서/논문
- Dive Club: Some (slightly nerdy) thoughts on AI and the future of design tooling — AI 디자인 툴 활용 가이드 | Podcast w. Ramp Senior Designer Diego Zaks — 협력하는 문화의 중요성
- Terrain Blog: Design Literacy in the Age of Intelligent Automation — 문해력만큼이나 중요해질 호기심, 연구된 큐레이션, 개인적인 신념, 기술의 결합
- Vela’s Product Memo Newsletter: Every Studio: Transforming Content Creation into Product Innovation — 미디어, 소프트웨어, AI의 원활한 통합이 어떤 결과를 가져오는지 보여주는 프로젝트
- AnchorCrafter: Animate CyberAnchors Saling Your Products via Human-Object Interacting Video Generation — 레퍼런스 제품과 상호 작용하는 사람들의 모습이 담긴 고품질 2D 동영상 생성
- Data Attribution for Text-to-Image Models by Unlearning Synthesized Images — 한 번도 예술 작품을 보지 못한 AI가 예술적 능력을 기를 수 있는지에 대한 연구
- DiffH2O: Diffusion-Based Synthesis of Hand-Object Interactions from Textual Descriptions — 텍스트 프롬프트를 통해 손-오브젝트 간 상호작용을 만들어 낼 수 있는 모델
- EgoAvatar: Egocentric View-Driven and Photorealistic Full-body Avatars — 다양한 동작을 수행하는 사람의 멀티뷰 비디오 퍼포먼스를 평가할 수 있는 벤치마크 소개
- GeneMAN: Generalizable Single-Image 3D Human Reconstruction from Multi-Source Human Data — 이미지를 고품질 3D 인간으로 쉽게 변환하는 3D 인간 재구성 프레임워크
- Introducing Spatiotemporal Skip Guidance (STG) for Video Diffusion Models — 트랜스포머 기반 비디오 확산 모델을 개선하기 위한 비학습 샘플링 안내 방법 시공간 스킵 안내(STG)를 소개
- I2VControl: Disentangled and Unified Video Motion Synthesis Control — 카메라 및 오브젝트 이동, 모션 브러시와 등의 모션 제어 작업을 통합하는 이미지 애니메이션 방법
- Quark: Real-time, High-Resolution, and Generalized Neural View Synthesis — 고품질, 고해상도, 실시간 신규 뷰 합성을 수행하는 새로운 신경 알고리즘
- L3DG: Latent 3D Gaussian Diffusion — 3D 가우시안 생성 디퓨전 모델
- ReVersion: Diffusion-Based Relation Inversion from Images & TALK-Act: Speaking Avatar Reenactment — 예시 이미지에서 특정 관계(“관계 프롬프트”로 표현됨)를 학습하는 것을 목표로 하는 관계 역학 방법론 제안
- SceneFactor: Factored Latent 3D Diffusion for Controllable 3D Scene Generation — 텍스트에서 3D 실내 장면 생성 및 편집할 수 있는 방법론 제안
- SOLAMI: Social Vision-Language-Action Modeling for Immersive Interaction with 3D Autonomous Characters — 3D 자율 캐릭터와의 몰입형 상호 작용을 위한 소셜 시각-언어-행동(VLA) 모델링 프레임워크
- TEXGen: a Generative Diffusion Model for Mesh Textures — UV 텍스처 공간에서 직접 학습하며 텍스트/이미지 기반 텍스처 합성을 가능하게 해주는 디퓨전 모델
- TriHuman: A Real-time and Controllable Tri-plane Representation for Detailed Human Geometry and Appearance Synthesis — 포즈 제어 기하학 합성법과 사실적인 렌더링 품질을 구현하는 삼면 표현법
- Video Depth without Video Models — 단일-이미지 디퓨전 모델을 활용해 비디오 깊이 추정기를 만드는 방법론 소개
가이드/튜토리얼
|
|
|
- 무엇이 가능한지 알기 위해 공학을 이해하고, 무엇이 아름다운지 알기 위해 디자인을 이해하고, 무엇이 바람직한지 알기 위해 심리학을 이해하고, 무엇이 가치 있는지 알기 위해 비즈니스를 이해하고, 이 모든 것을 행동으로 옮길 용기를 가진 사람이 되세요 (@keshavchan)
- 행복이란 것은 없습니다. 현재에 대한 연약한 만족감만 존재할 뿐이며, 불행한 순간 또는 무언가를 원하는 고통이 찾아오면 그것을 얻거나 극복할 때까지 그 만족감은 깨집니다. 그러니, 이유 없는 감사, 동기 없는 아름다움, 요구 없는 사랑을 실천하시길 바랍니다 (@naval)
- 좋은 감각은 타고나는 것이 아니라 호기심, 공개 작업, 연습을 통해 습득 되는 것입니다. 자신을 좋은 환경에 두면, 자연스럽게 좋은 감각을 인식하고 만들어 갈 수 있게 됩니다 (@raphaelsalaja)
- 기술을 올바르게 적용한다면, 모두가 풍요로운 삶을 살 수 있을 만한 충분한 에너지와 물질이 있다는 것이 보편적인 사실입니다 (@simonlast)
- 성장은 믿음과 내면의 힘에 의지해야 하는 숨겨지고 조용한 공간에서 일어납니다. 어둠은 무덤이 아니라 새로운 시작을 위한 토대입니다 (@drex_dsgn)
- 지금 당장 할 수 있는 일 한 가지가 아니라 1년치 기술 습득, 업무, 성장을 머릿속에 담고 있기 때문에 버겁다고 느껴지는 것입니다 (@thedankoe)
|
|
|
여러분의 참여를 환영합니다.
'데일리 노트' 뉴스레터는 독자들의 적극적인 참여를 전제로 기획되었습니다. 의견 남기기를 통해 여러분들의 이야기를 들려주세요. 뉴스레터 내용에 대한 의견, 다른 크리에이터분들에게 선보이고 싶은 제품/서비스, 공유하고 싶은 이야기, 협업하고 싶은 내용 모두 환영합니다. |
|
|
|